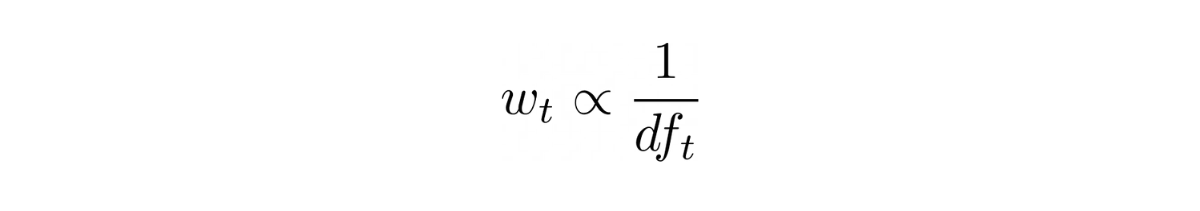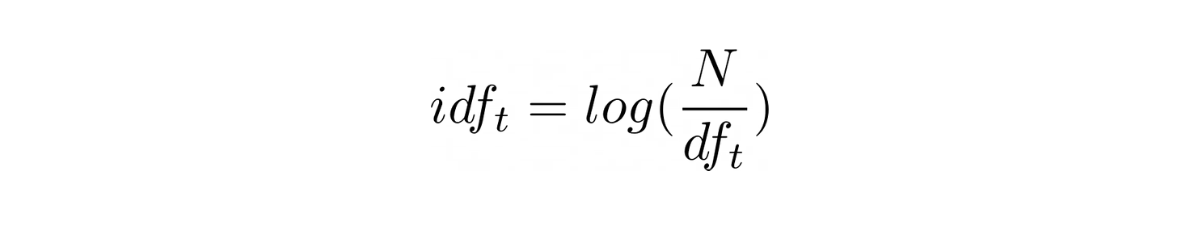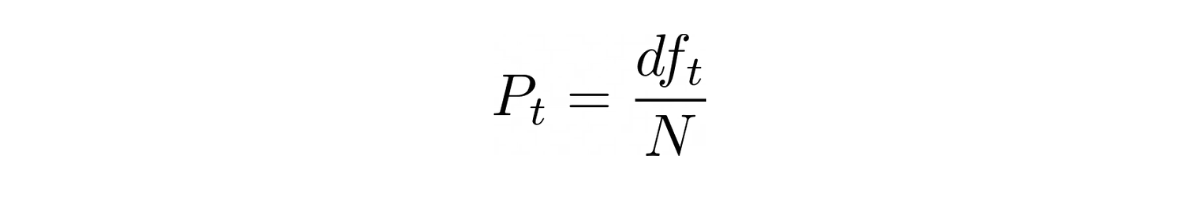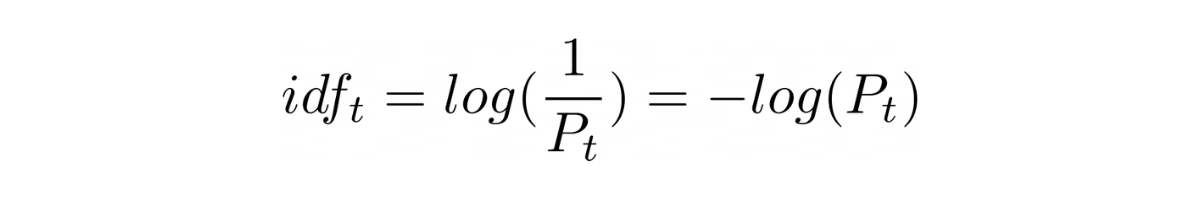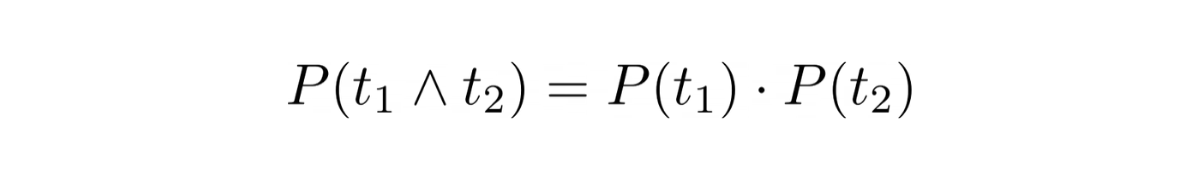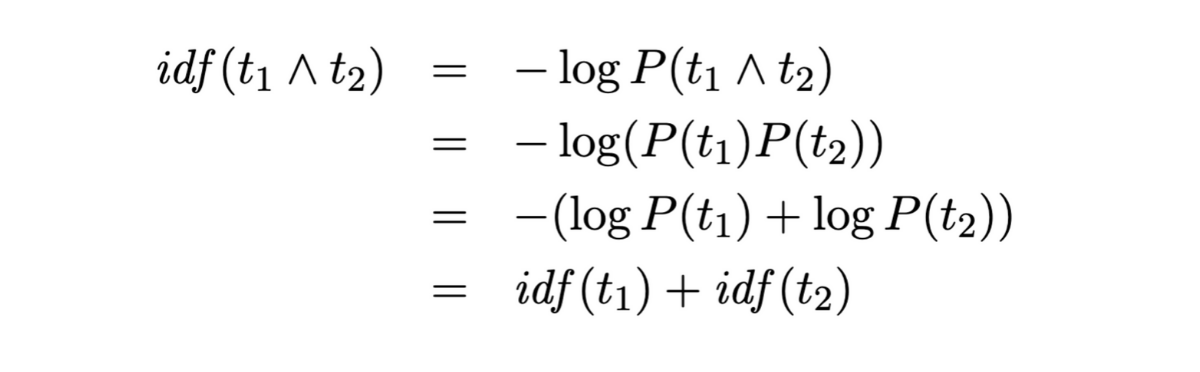The Intuition Behind IDF
Source: https://arpitbhayani.me/blogs/idf Date: 2020-03-10
Explore Inverse Document Frequency (IDF), a key concept in search & text mining. Learn how it quantifies term rarity and its connection to probability.
TF-IDF is one of the most popular measures that quantify document relevance for a given term. It is extensively used in Information Retrieval (ex: Search Engines), Text Mining and even for text-heavy Machine Learning use cases like Document Classification and Clustering. Today we explore the better half of TF-IDF and see its connection with Probability, the role it plays in TF-IDF and even the intuition behind it.
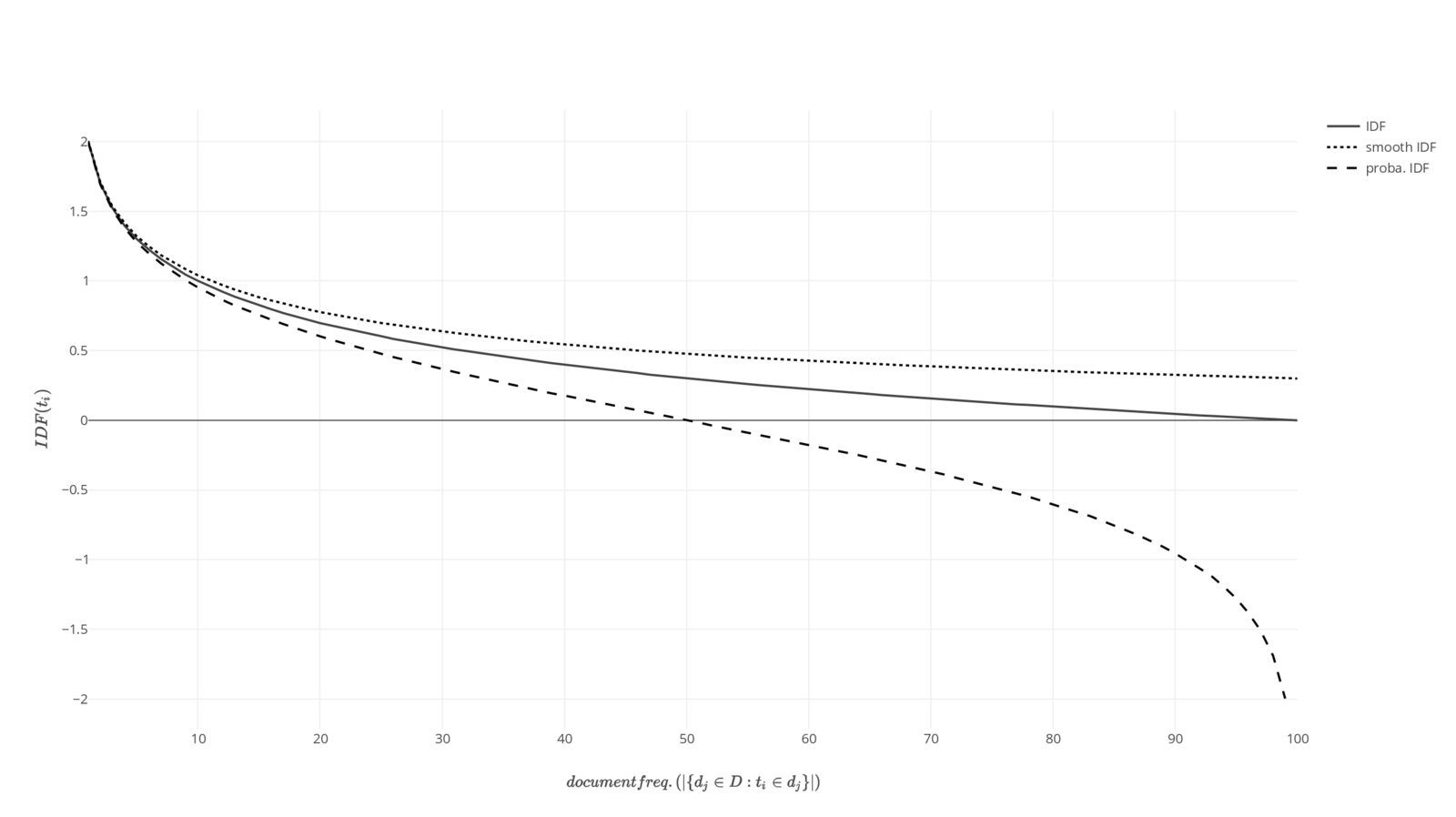
Inverse Document Frequency (IDF) is a measure of term rarity which means it quantifies how rare the term, in the corpus, really is (document collection); higher the IDF, rarer the term. A rare term helps in discriminating, distinguishing and ranking documents and it contributes more information to the corpus than what a more frequent term (like , and ) does.