Stream Continuation
Last updated on March 25, 2026
Edward Stream Continuation Architecture - Deep Dive
Principal Engineer's Technical Reference
Easy to digest HLD
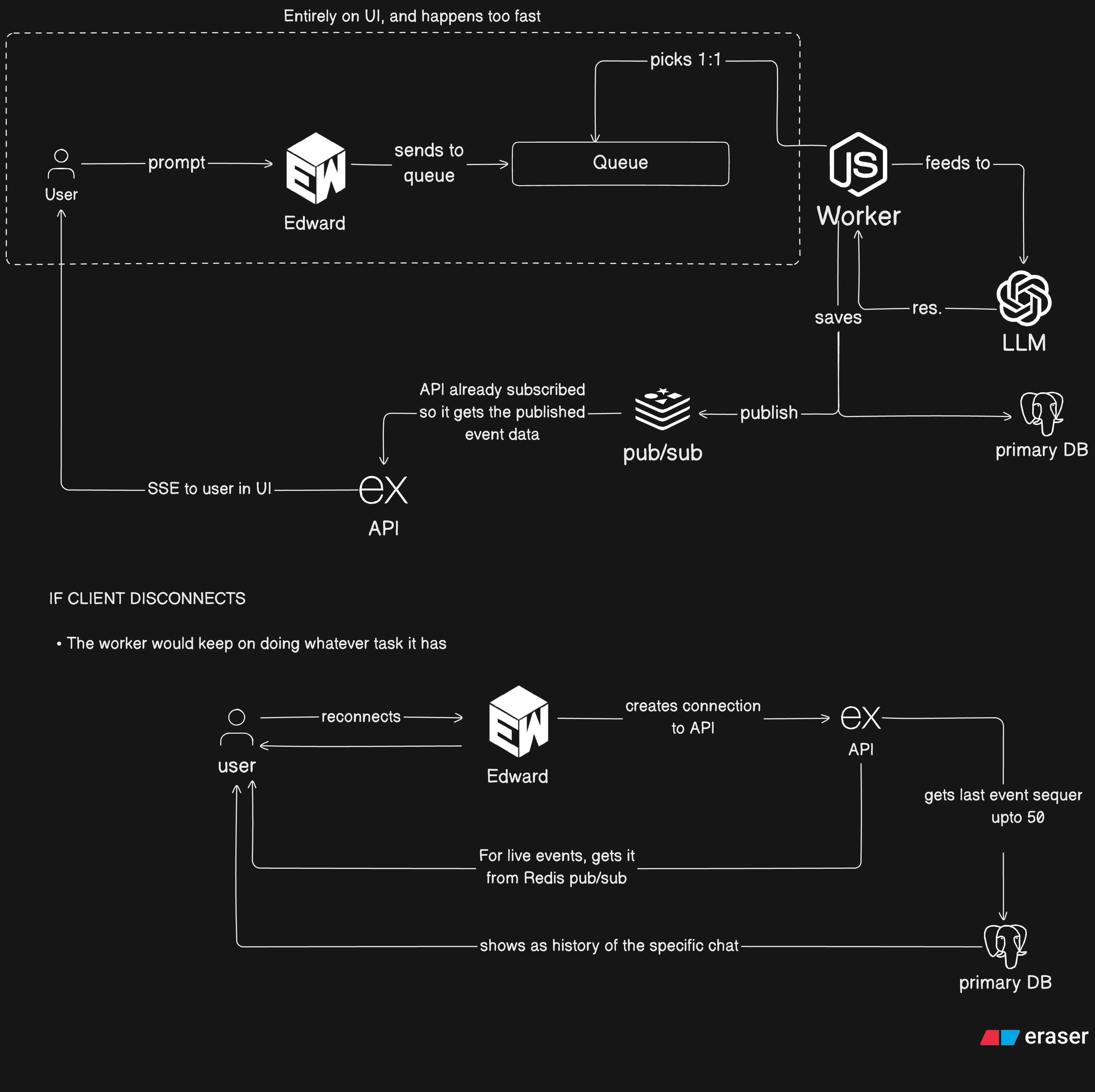
Table of Contents
- Executive Summary
- Architecture Principles
- Core Components Deep Dive
- Stream Continuation Flow
- Checkpoint Mechanism
- Event Sourcing & Replay
- Frontend Reconnection Strategy
- Worker Resumption
- Failure Modes & Recovery
- Infrastructure Cross-Questions
- Key Files Reference
1. Executive Summary
What is Stream Continuation?
Stream Continuation is Edward's resilience architecture that enables:
- Seamless reconnection after client disconnects (page refresh, network blip, tab switch)
- Worker crash recovery without losing in-progress code generation
- Exact state replay from any point in the stream using cursor-based tracking
- Multi-turn agent loop checkpointing for long-running operations
Why This Matters
Without stream continuation:
- Page refresh = lost work, user frustration
- Worker restart = orphaned runs, inconsistent state
- Network hiccup = incomplete code generation
- Long operations = no recovery from mid-execution failures
With stream continuation:
- Durable execution: Every event persisted, every state checkpointed
- Resumable UX: Users can refresh/reconnect without losing progress
- Operational resilience: Workers can restart without data loss
- Audit trail: Complete event history for debugging and compliance
2. Architecture Principles
2.1 Event Sourcing
All stream events are persisted as an immutable log:
Benefits:
- Exact replay from any sequence number
- Audit trail for debugging
- Supports multiple reconnections
- Enables time-travel debugging
2.2 Dual-Channel Delivery
Events delivered via two channels simultaneously:
Why Both?
- PostgreSQL: Durable, queryable, supports historical replay
- Redis Pub/Sub: Low-latency, push-based, supports many subscribers
2.3 Cursor-Based Resumption
Frontend tracks last processed event:
Resumption Flow:
- Page loads → read cursor from sessionStorage
- Open SSE stream with
?lastEventId=seq:12345 - Backend replays events from PostgreSQL where
seq > 12345 - Subscribe to Redis for live events
- Update cursor on each new event
2.4 Checkpoint-Based Worker Resumption
Agent loop state checkpointed on continuation turns:
Persisted to: runs.metadata.resumeCheckpoint
3. Core Components Deep Dive
3.1 Event Persistence Layer
File: apps/api/services/runs/runEvents.service.ts
Key Design Decisions:
| Decision | Rationale |
|---|---|
Sequential seq numbers | Enables cursor-based replay, ordering guarantee |
| Dual write (Postgres + Redis) | Durability + real-time delivery |
| Envelope pattern | Decouples storage format from event schema |
| Optional publisher | Allows testing without Redis dependency |
3.2 SSE Streaming with Replay
File: apps/api/services/run-event-stream-utils/service.ts
Core Function: streamRunEventsFromPersistence()
Replay Logic:
Buffering During Replay:
Why Buffer?
- Live events may arrive during replay
- Need to prevent duplicates
- Need to maintain ordering (seq-based)
3.3 SSE Backpressure Handling
File: apps/api/services/sse-utils/service.ts
Problem: Slow clients can cause memory buildup
Solution: Queue-based backpressure with graceful degradation
Backpressure Configuration:
Graceful Degradation:
- Queue builds up → monitor size
- Exceeds threshold → trigger
onSlowClient - Close stream gracefully → client can reconnect
3.4 Worker Event Capture
File: apps/api/services/runs/agent-run-worker/processor.helpers.ts
Problem: Worker needs to capture SSE stream and persist events
Solution: Create mock Response object that intercepts writes
Why This Pattern?
- Decouples stream session from persistence mechanism
- Enables testing without actual HTTP response
- Serializes event persistence (prevents race conditions)
- Tracks failures for finalization
4. Stream Continuation Flow
4.1 Normal Flow (No Interruption)
4.2 Client Disconnect + Reconnect
4.3 Worker Crash + Restart
5. Checkpoint Mechanism
5.1 Checkpoint Structure
File: apps/api/services/runs/runMetadata.ts
Stored in: runs.metadata.resumeCheckpoint (JSONB column)
5.2 When Checkpoints Are Created
File: apps/api/services/chat/session/loop/agentLoop.turnOutcome.ts
Checkpoints created on continuation turns (when agent loop continues):
Continuation Scenarios:
| Scenario | When | Why Checkpoint |
|---|---|---|
| Tool Results Continuation | Tools called but no code output | Need to send tool results back to LLM |
| No-Progress Nudge | No tools called, no output | Need to send nudge prompt |
NOT Checkpointed:
- Initial turn (turn 0)
- Final turn (when loop exits)
- Turns that produce code output
5.3 Checkpoint Persistence Flow
File: apps/api/services/runs/agent-run-worker/processor.session.ts
5.4 Checkpoint Usage on Worker Restart
File: apps/api/services/chat/session/loop/agentLoop.runner.ts
5.5 Checkpoint Cleanup
File: apps/api/services/runs/agent-run-worker/processor.finalize.ts
On successful completion:
Why Clear?
- Run is complete, no need to resume
- Reduces metadata size
- Prevents accidental replay of completed runs
6. Event Sourcing & Replay
6.1 Event Schema
File: packages/shared/src/streamEvents.ts
Event Types:
| Category | Events |
|---|---|
| Lifecycle | meta (SESSION_START, TURN_START, TURN_COMPLETE, SESSION_COMPLETE) |
| Content | text, thinking_*, file_* |
| Sandbox | sandbox_*, install_*, command |
| Tools | , |
6.2 Event Persistence
Database Schema:
Append Function:
6.3 Event Replay Query
File: apps/api/services/run-event-stream-utils/service.ts
Query Pattern:
6.4 Replay Batching
Why Batch?
- Large runs may have thousands of events
- Don't overwhelm client with single massive response
- Allow progressive rendering
Batching Logic:
Multiple Batches:
- First batch: 500 events
- If more events exist, loop continues
- Next iteration: next 500 events
- Continues until all events replayed
7. Frontend Reconnection Strategy
7.1 Cursor Persistence
File: apps/web/stores/chatStream/cursorPersistence.ts
Storage Strategy:
| Layer | Purpose | Lifetime |
|---|---|---|
| In-memory Map | Fast access during session | Tab lifetime |
| sessionStorage | Persistence across refresh | Tab lifetime (survives refresh) |
Why Not localStorage?
- Cursors are session-specific
- Don't persist across browser restarts
- Avoid stale cursors for old runs
7.2 Stream Resumption
File: apps/web/stores/chatStream/resumeRunStream.ts
7.3 API Client
File: apps/web/lib/api/chat.ts
Request Format:
7.4 Page-Level Orchestration
File: apps/web/hooks/chat/useChatPageOrchestration.ts
Active Run Lookup:
Lookup Strategy:
| Mode | Attempts | Use Case |
|---|---|---|
| Aggressive | 6 | Page load, user expects active run |
| Single | 1 | Background check |
| Defer | 0 | Streaming already in progress |
7.5 Stream Processor with Replay
File: apps/web/lib/streaming/processors/chatStreamProcessor.ts
Built-in Replay:
Why Client-Side Replay?
- Backend stream may end prematurely
- Client detects incomplete session
- Automatic retry with backoff
- Merges results seamlessly
8. Worker Resumption
8.1 Worker Lifecycle
File: apps/api/services/runs/agent-run-worker/processor.ts
Startup:
8.2 Checkpoint Detection
8.3 Resumption Flow
8.4 Finalization
File: apps/api/services/runs/agent-run-worker/processor.finalize.ts
On Success:
On Failure:
Why Keep Checkpoint on Failure?
- Allows manual retry from checkpoint
- Preserves state for debugging
- Can be cleared by explicit retry logic
9. Failure Modes & Recovery
9.1 Failure Mode Matrix
| Failure Mode | Detection | Recovery | Data Loss |
|---|---|---|---|
| Client disconnect | req.close event | Reconnect with cursor | None |
| Slow client | Backpressure queue | Graceful close | None (events persisted) |
| Worker crash | Job timeout | Queue retry + checkpoint | Minimal (since last checkpoint) |
| Redis unavailable | Connection error | Fallback to PostgreSQL polling | None |
| PostgreSQL unavailable | Query error | Retry with backoff | Temporary (events buffered) |
| Stream timeout | Guard timer | Terminate with reason |
9.2 Client Disconnect Handling
File: apps/api/services/run-event-stream-utils/service.ts
What Happens:
- Client closes connection (refresh, navigate away)
- Backend receives
req.closeevent - Unsubscribe from Redis pub/sub
- Stop heartbeats
- Close response gracefully
- Worker continues execution (independent of client connection)
9.3 Slow Client Handling
File: apps/api/services/run-event-stream-utils/service.ts
Detection:
- Write queue exceeds threshold
res.write()returnsfalse(backpressure)- Queue not draining fast enough
Recovery:
- Close stream gracefully
- Client can reconnect with cursor
- Events already persisted → replay on reconnect
9.4 Worker Crash Recovery
File: apps/api/services/runs/agent-run-worker/processor.ts
Crash Detection:
- Worker process dies (OOM, panic, etc.)
- Job queue detects timeout
- Run remains in "RUNNING" state
Recovery:
- Queue retries job (configurable retries)
- New worker picks up job
- Load run from DB
- Check for checkpoint in metadata
- Resume from checkpoint.turn
What's Lost:
- Work since last checkpoint
- Typically: partial turn execution
- Events persisted before crash are safe
9.5 Stream Timeout
File: apps/api/services/chat/session/orchestrator/streamGuards.ts
On Timeout:
- Abort controller triggered
- Agent loop stops
- Termination reason set to
STREAM_TIMEOUT - Session finalized with timeout reason
- Client receives error event
9.6 Redis Unavailable
File: apps/api/lib/redisPubSub.ts
Fallback Strategy:
- Events still persisted to PostgreSQL
- Client reconnects → replay from PostgreSQL
- Live events missed during Redis outage
- Mitigation: Poll PostgreSQL for new events
10. Infrastructure Cross-Questions
10.1 PostgreSQL
Q: What's the event volume per run?
Typical run:
- Meta events: 5-10 (session start, turn start/complete x5, session complete)
- Text events: 50-200 (narrative, explanations)
- File events: 10-50 (file_start, file_content xN, file_end)
- Command events: 5-20 (command execution results)
- Total: 70-300 events per run
Q: What's the storage requirement?
Per run estimate:
- Event envelope: ~200 bytes overhead
- Event payload: ~500 bytes average (varies widely)
- Per event: ~700 bytes
- Per run (200 events): ~140 KB
At 10,000 runs/day:
- Daily: 1.4 GB
- Monthly: 42 GB
- Yearly: 500 GB
Q: Should we partition the run_events table?
Recommendation: Yes, partition by created_at (monthly partitions)
Benefits:
- Faster cleanup (drop old partitions)
- Improved query performance (partition pruning)
- Easier backup/restore
Q: What indexes are needed?
10.2 Redis
Q: What's the Redis memory footprint?
Pub/sub channels:
- One channel per active run:
edward:run-events:{runId} - Channel name: ~50 bytes
- Subscriber overhead: ~100 bytes per subscriber
- Per active run: ~150 bytes
At 1,000 concurrent runs:
- Channel memory: ~150 KB (negligible)
Q: What about event buffering?
Events are NOT buffered in Redis (only published):
- Publisher sends event → all subscribers receive
- No persistence in Redis
- PostgreSQL is the source of truth
Q: Redis cluster vs standalone?
Recommendation: Standalone for pub/sub
Why:
- Pub/sub doesn't benefit from clustering (messages not persisted)
- Simpler deployment
- Lower latency
Failover:
- Sentinel for automatic failover
- Clients reconnect on failover
- Events persisted to PostgreSQL during outage
Q: What's the pub/sub latency?
Typical latency:
- Publish to subscriber: <1ms (same region)
- 99th percentile: <5ms
Impact:
- Live events arrive within milliseconds
- Replay from PostgreSQL is the bottleneck (not Redis)
10.3 SSE Infrastructure
Q: How many concurrent SSE connections?
Estimate:
- Active runs: 1,000
- Connections per run: 1-3 (user may have multiple tabs)
- Concurrent connections: 1,000-3,000
Q: Can a single server handle this?
Node.js SSE capacity:
- Memory per connection: ~10-50 KB
- CPU per connection: minimal (event-driven)
- Single server: 10,000+ connections feasible
Q: What about horizontal scaling?
Challenge: SSE connections are sticky (can't load balance mid-stream)
Solutions:
-
Sticky sessions (recommended)
- Load balancer routes by cookie/session
- Same server handles entire stream
- Simple, effective
-
Connection migration
- On server shutdown, notify clients
- Clients reconnect to new server
- Complex, rarely needed
-
WebSocket + migration
- Use WebSocket instead of SSE
- Supports connection migration
- More complex protocol
Q: What's the heartbeat strategy?
Why Heartbeats?
- Keep connection alive (prevent timeout)
- Detect dead connections
- Load balancers may close idle connections
Q: How to handle connection limits?
Browser limits:
- Chrome: 6 connections per domain
- Firefox: 6 connections per domain
- Safari: 6 connections per domain
Mitigation:
- Single SSE connection per chat
- Reuse connection for multiple runs
- Use domain sharding if needed (not recommended)
10.4 Worker Scaling
Q: How many workers?
Formula:
Typical:
- Concurrent runs: 1,000
- Runs per worker: 10-50 (depends on LLM latency)
- Workers needed: 20-100
Q: Worker autoscaling?
Metrics to track:
- Queue depth (Redis)
- Average run duration
- Worker CPU/memory
Scaling policy:
- Scale up: Queue depth > threshold for 2 minutes
- Scale down: Queue depth = 0 for 10 minutes
Q: What about worker affinity?
No affinity needed:
- Workers are stateless
- State in PostgreSQL + checkpoint
- Any worker can process any job
10.5 Data Retention
Q: How long to keep events?
Recommendation: 30 days
Why:
- Supports debugging recent issues
- Allows replay for active users
- Compliance (audit trail)
Cleanup strategy:
Q: What about checkpoint retention?
Recommendation: Clear on completion, keep on failure
Why:
- Completed runs don't need checkpoint
- Failed runs may need manual retry
- Checkpoints are small (few KB)
10.6 Monitoring
Q: What metrics to track?
Stream Health:
stream_reconnect_count: Reconnections per runstream_replay_events: Events replayed per reconnectstream_duration_ms: Total stream durationstream_termination_reason: Distribution of termination reasons
Checkpoint Health:
checkpoint_created_count: Checkpoints createdcheckpoint_resume_count: Runs resumed from checkpointcheckpoint_turn_distribution: Turns per checkpoint
Event Volume:
events_persisted_count: Events per runevents_replay_lag_ms: Time to replay eventsredis_pubsub_latency_ms: Pub/sub latency
Q: What alerts to set?
| Metric | Threshold | Action |
|---|---|---|
stream_reconnect_count > 5 | Per run | Investigate network issues |
checkpoint_resume_count > 10% | Of runs | Investigate worker stability |
events_replay_lag_ms > 5000 | P99 | Optimize replay queries |
redis_pubsub_latency_ms > 100 | P99 | Check Redis health |
11. Key Files Reference
Core Orchestration
| File | Purpose | Lines |
|---|---|---|
apps/api/services/runs/runEvents.service.ts | Event persistence | ~40 |
apps/api/services/run-event-stream-utils/service.ts | SSE streaming + replay | ~250 |
apps/api/services/sse-utils/service.ts | SSE backpressure handling | ~200 |
apps/api/services/runs/agent-run-worker/processor.ts | Worker execution | ~350 |
apps/api/services/runs/agent-run-worker/processor.helpers.ts |
Checkpoint & Continuation
| File | Purpose | Lines |
|---|---|---|
apps/api/services/runs/runMetadata.ts | Checkpoint schema | ~100 |
apps/api/services/runs/agent-run-worker/processor.session.ts | Checkpoint persistence | ~100 |
apps/api/services/chat/session/loop/agentLoop.runner.ts | Agent loop with checkpoint | ~200 |
apps/api/services/chat/session/loop/agentLoop.turnOutcome.ts | Continuation logic | ~250 |
Frontend
| File | Purpose | Lines |
|---|---|---|
apps/web/stores/chatStream/cursorPersistence.ts | Cursor storage | ~50 |
apps/web/stores/chatStream/resumeRunStream.ts | Stream resumption | ~150 |
apps/web/lib/api/chat.ts | SSE API client | ~100 |
apps/web/lib/streaming/processors/chatStreamProcessor.ts | Stream processing | ~400 |
apps/web/hooks/chat/useChatPageOrchestration.ts |
Shared Types
| File | Purpose | Lines |
|---|---|---|
packages/shared/src/streamEvents.ts | Event type definitions | ~250 |
Infrastructure
| File | Purpose | Lines |
|---|---|---|
apps/api/lib/redisPubSub.ts | Redis pub/sub | ~80 |
apps/api/lib/redis.ts | Redis client creation | ~20 |
Tests
| File | Purpose |
|---|---|
apps/api/tests/services/runs/agentRun.processor.session.test.ts | Checkpoint tests |
apps/api/tests/services/runs/runMetadata.test.ts | Metadata parsing tests |
apps/api/tests/controllers/chat/streamSession.shared.test.ts | Continuation prompt tests |
apps/api/tests/services/chat/runEventStream.utils.service.test.ts | Stream replay tests |
Appendix A: Glossary
| Term | Definition |
|---|---|
| Checkpoint | Snapshot of agent loop state for resumption |
| Cursor | Last processed event ID (client-side) |
| Event Sourcing | Pattern of persisting all state changes as events |
| Replay | Re-emitting historical events on reconnection |
| SSE | Server-Sent Events (one-way streaming from server to client) |
| Turn | Single iteration of agent loop (LLM call + tool execution) |
| Worker | Background process that executes agent runs |
Appendix B: Sequence Diagrams
B.1 Normal Stream Flow
B.2 Reconnection Flow
Appendix C: Configuration Reference
Environment Variables
| Variable | Default | Description |
|---|---|---|
STREAM_GUARD_TIMEOUT_MS | 1200000 | Stream timeout (20 min) |
MAX_AGENT_CONTINUATION_PROMPT_CHARS | 20000 | Continuation prompt limit |
MAX_AGENT_TURNS | 10 | Max agent loop iterations |
MAX_AGENT_TOOL_CALLS_PER_TURN | 10 | Tool budget per turn |
MAX_AGENT_TOOL_CALLS_PER_RUN |
Redis Channels
| Channel | Purpose |
|---|---|
edward:run-events:{runId} | Live event pub/sub |
edward:run-cancel:{runId} | Cancel signal |
agent-runs | Worker job queue |
Storage Keys
| Key | Purpose |
|---|---|
sse_cursor:{chatId}:{runId} | Frontend cursor |
Document Version: 1.0
Last Updated: March 25, 2026
Author: Principal Engineering Review